
How to Implement AI in Legacy Enterprise Systems
When we talk about modernizing enterprise software, it often may sound like you can just plug a modern neural network into an old mainframe and watch the magic happen. Anyone who has actually written code for an old ERP platform knows that it is a fantasy. The reality is messy, frustrating, and usually involves dealing with systems that were built before half your current engineering team was born. Yet discarding these multimillion-dollar setups is not an option for most major companies, as they are simply too deeply embedded in daily operations.
This article analyzes the actual architectural work required to make old databases and modern machine learning models talk to each other. We will look at the actual integration patterns, data pipelines, and operational guardrails needed to make this happen without crashing your core infrastructure.
Data Friction in Older Architectures
The first issue is always related to the data. Modern machine learning libraries like TensorFlow or PyTorch expect clean, structured, and instantly accessible data points. Older enterprise systems usually store information in proprietary formats inside localized SQL servers or mainframe environments.
Valuable operational details often end up trapped in unindexed text fields, archaic logs processed in batches, or nested stored procedures. If you try to point a modern AI model at these raw sources, it is most likely going to fail. The data is simply too fragmented for the model to parse effectively.
Next, let’s discuss the timing issue. AI integration thrives on real-time event streaming. Legacy software, however, usually relies on batch processing. It is common to see systems that only sync data once every 24 hours to preserve computing power. Forcing a real-time predictive model to rely on data that updates only overnight creates an immediate operational mismatch. Furthermore, running heavy, unoptimized queries on a production database during peak hours can easily slow down or crash the entire monolithic system.
Practical Integration Patterns
You almost never want to modify the core code of a stable, legacy system to support AI directly. The risk of breaking critical business logic is too high. Instead, engineers build middle layers that allow both environments to coexist.
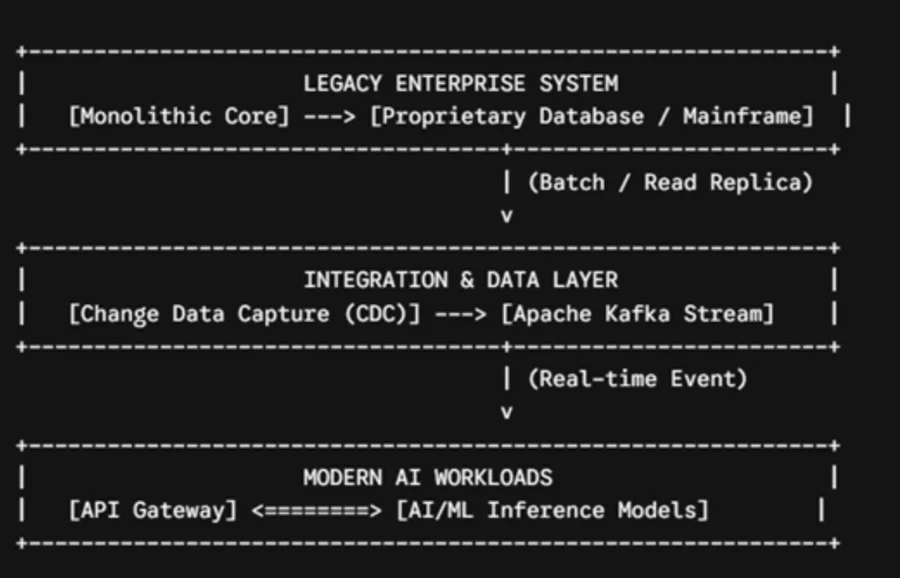
One of the most reliable approaches is the wrapper pattern. Developers create an API facade around the legacy platform using modern environments like Python or Node.js. This middleware queries the old system via existing database connectors or terminal emulators, translates legacy data formats into standard JSON web requests, and passes them to the AI components. This keeps the legacy core isolated from direct AI workloads. If you decide to modernize the underlying software later, your AI integration remains intact because the API wrapper shields it from the changes.
Another approach focuses on data pipelines. To feed machine learning models without degrading database performance, teams use Change Data Capture tools. These tools read the database transaction logs directly and stream updates immediately to a cloud data warehouse like Snowflake or Amazon Redshift. This gives your models access to fresh data without placing any extra load on your primary operational systems.
The Integration Workflow
Deploying artificial intelligence alongside older infrastructure requires a methodical engineering approach. Rushing into model training without preparing the foundation is a quick way to stall a project.
First, engineers must audit the existing technical debt. This means documenting old database schemas, checking network bandwidth between on-premises servers and the cloud, and reviewing security protocols.
Next, teams establish the data pipeline. If the legacy system cannot handle continuous data streaming, the engineering team extracts the data into a high-performance read-replica database. This replica serves as a dedicated environment for data engineering, keeping the live application safe from performance drops.
Once the pipelines are ready, data scientists train the models in scalable cloud environments using historical data exported from the legacy platform. After training, the model is wrapped in a containerized environment using Docker or Kubernetes and exposed through an API gateway. When the legacy system needs a prediction, it sends a quick request to the gateway, gets a response in milliseconds, and continues its standard execution path.
Managing Technical Friction and Operational Risk
Bridging the gap between modern tech stacks and legacy environments requires specific engineering workarounds. Modern components running on Python must interact with older codebases written in COBOL, older versions of Java, or C++. Containerized microservices solve this by acting as communication proxies between the two eras.
Similarly, real-time message brokers like Apache Kafka must interface with old batch processing schedules. Using Change Data Capture engines to track database logs directly resolves this bottleneck. Finally, relational databases like Oracle can feed modern vector databases through scheduled extract, transform, and load pipelines that sync vital data into cloud warehouses.
Operating and maintaining older enterprise software consumes the vast majority of an organization’s IT resources and engineering attention. Because these systems are already carrying such a heavy operational load, introducing artificial intelligence has become quite challenging. One misconfiguration can disrupt core services that the entire company relies on daily. This means engineering, QA, and DevOps teams not only focus on model accuracy but also have to carefully mitigate systemic risks to keep the baseline infrastructure stable.
- Security and compliance
Legacy applications usually run inside strict, isolated on-premises perimeters. Connecting these systems to cloud-based AI services requires secure networking solutions, such as dedicated VPN tunnels or private cloud connections. Any data leaving the legacy environment must also be anonymized or encrypted to satisfy regional data protection laws.
- System load balancing
AI models require significant computing power during inference. If the AI system queries legacy databases too frequently, it can quickly exhaust available connection pools. Implementing caching layers with Redis and setting up strict rate limiting on API gateways keeps older enterprise software stable and responsive under heavy use.
- Long-term system maintenance
Deploying the initial integration is just the first step. Long-term success requires a clear operational strategy to manage both the new AI components and the underlying legacy platform.
Over time, business environments change, and the accuracy of machine learning models can drop, which is a problem known as model drift. DevOps teams need to set up monitoring tools to track prediction accuracy and system latency. When performance drops below an acceptable threshold, it should trigger an automated retraining cycle using fresh data from the legacy system.
Another challenge is documentation. Legacy software documentation is notoriously poor or outdated. When you add AI to the mix, system architects must maintain accurate maps of data lineage, API contracts, and failure protocols. This ensures that both infrastructure engineers and data scientists can troubleshoot issues effectively when things go wrong.
Bottom Line
Leveraging the advantages of AI implementation in legacy systems should not necessarily be a high-risk and expensive rewrite of your core business software. If you use practical integration patterns such as microservices wrappers, data pipelines, and API gateways, you can deploy advanced machine learning models alongside your stable, older architectures.
The secret is to keep the legacy core protected from heavy AI workloads, maintain clean data pipelines, and establish clear security boundaries. A smart strategy allows you to turn rigid, old applications into responsive, data-driven systems.


